
This is now a pretty decent endpoint for Influx Line Protocol, but there are a few features that are missing for something to be practical for normal usage. One of those is that the application should not lose data just because it does not recognize the metric, tag, or field. Fields and tags that are not recognized will be added to the _fields and _tags columns of the metric, but a metric that is not recognized will currently be thrown away.
This was intentional in the original design. Partially because it simplified the implementation and partially since you want to be able to select what to record. If you, however, set up an endpoint you might want to collect everything first and only later start to become more selective about what to store once you see what metrics arrive to the endipoint. Since pg_influx store metrics in tables, it is necessary to create new tables for each new metric, so let’s add this feature to pg_influx.
As always, you will find the code for pg_influx at GitHub.
A reasonable list of requirements is:
- If a metric arrives for an unrecognized metric, a table for the metric should be created.
- The table definition should have a default format.
- The default format for the tables should be configurable by the administrator.
- It should be possible to configure the extension to not create new tables for unrecognized metrics.
Default Table Definition
We already defined a default definition for the table in Parsing InfluxDB Line Protocol, which is similar to how InfluxDB uses the fields. The default table definition for a metric is simply a table with three columns:
_timebeing aTIMESTAMP WITH TIMEZONEtype_fieldsbeing aJSONBstoring the values of the fields_tagsbeing aJSONBstoring the tags of the metric
There are two basic ways we can create a new table whenever a metric for an unrecognized metric name is read:
- Keep a template for the default table available and make a copy of it when an unrecognized metric name is read.
- Call a procedure for creating the table whenever an unrecognized metric name is read.
Since the latter alternative is more flexible, and also a little more interesting because it provides an opportunity to take a closer look at some PostgreSQL internals, let’s consider how to implement automatic table creation using a function. First, you need to write the creation function, then you need to extend the installation script to work with this function, then you need to extend the InfluxDB listener to call this function when a metric for an unrecognized table is received.
Writing the Table Creation Function
To make it possible to customize the function, it is added as the _create in the schema where the metrics are stored. So, for example, if metrics are stored in influx schema, the function will be named influx._create. The function would name a metric name as input, create the table, and return the OID of the created table. If the OID is invalid (that is, zero), the line will be skipped.
We could just as well construct a CREATE TABLE statement and execute it using SPI interface, as we have done previously, but this is such a simple usage that we can avoid the parsing and go directly to the DefineRelation call, which is more efficient. A potential drawback of this is that if the ABI changes (the field names and/or the struct size) changes, and if the parameters for the DefineRelation call changes, this might cause unexpected problems. The ABI regarding CreateStmt and DefineRelation is, however, very stable (DefineRelation changed last time in 2015 and CreateStmt changed last time in 2017), so this should not create problems and will also be noticed if you try to compile the extension for a new version of PostgreSQL.
We can implement this function in PL/pgSQL, but it is straightforward to implement in C as well, and is a great opportunity to look into some PostgreSQL internals. The code for creating a table with the above definition would look like this:
#include <postgres.h>
#include <fmgr.h>
#include <catalog/pg_type_d.h>
Datum default_create(PG_FUNCTION_ARGS) {
Name metric = PG_GETARG_NAME(0);
Oid nspoid = get_func_namespace(fcinfo->flinfo->fn_oid);
CreateStmt *create = makeNode(CreateStmt);
ObjectAddress address;
create->relation =
makeRangeVar(get_namespace_name(nspoid), NameStr(*metric), -1);
create->tableElts =
list_make3(makeColumnDef("_time", TIMESTAMPTZOID, -1, InvalidOid),
makeColumnDef("_tags", JSONBOID, -1, InvalidOid),
makeColumnDef("_fields", JSONBOID, -1, InvalidOid));
address = DefineRelation(create, RELKIND_RELATION, GetUserId(), NULL, NULL);
return address.objectId;
}To understand what is going on here, we need to take a slightly deeper look into the parser part of PostgreSQL, in particular, the output of the parser and how utility statements (like CREATE TABLE) are executed as well as how objects are deal with inside PostgreSQL.
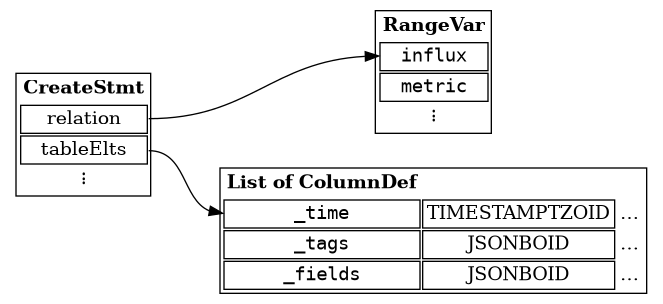
CreateStmt structure for CREATE statementThe PostgreSQL Parser and Parse Nodes
The SQL parser inside PostgreSQL reads text input and produces parse nodes which are then passed to functions that do the real work. The parse nodes are just structures with information about the construction seen in a form that is suitable for the executor. All these parse nodes are defined in the header file src/include/nodes/parsenodes.h. The CreateStmt parse contains a lot of information used for creating many different kinds of objects, but we’re only interested the fields relation and tableElts.
If you parse a statement like the CREATE statement below, you will end up with a structure looking as in Figure 1.
create table influx.metric (
_time timestamptz,
_tags jsonb,
_fields jsonb
);The relation field contains the table we are going to create, as a range variable. Range variables are used to represents tables in FROM clauses but are also used to represent tables in utility statements like CreateStmt. Creating a range variable is straightforward using the makeRangeVar function with the schema name, the relation name, and the location. The schema name and table name is self-explanatory, but the location parameter is used to point to a location in the source text when parsing SQL. Since we are not doing this, we just pass in -1, which represents an unknown location.
Next step consists of building the column definitions using the makeColumnDef function. The first two parameters are the name of the column as a C string and the OID of the type of the column. Most of these are pre-defined in the catalog/pg_type_d.h header file, which we include, so we can use TIMESTAMPTZOID and JSONBOID directly for these parameters. The last two parameters are intended for more advanced usage: the type modifier and the collation. We do not cover these here.
Once the parse node is constructed, it is passed to the DefineRelation function, which will create the corresponding object (in this case, a normal relation) using the CreateStmt structure that we constructed, the relation kind, the owner identifier, the object address of the type, and the query string, and it will return an object address of the newly created object. In this case, a relation.
The concept of a relation is not restricted to tables and PostgreSQL calls a lot of other constructs “relations” as well: indexes, sequences, and views are some other examples of relations in this sense. For this reason, you have to pass the relation kind to the function: in our case, we use RELKIND_RELATION, which is a normal table.
The owner identifier is simply the OID of the role that owns the object. In this case, you can just use GetUserId() to get the OID of the current effective user. The two additional parameters that can be passed in are the object address of the type, and the query string. Since we are not using these, we just pass in NULL here.
Object addresses are used to refer to different kinds of objects during parsing and execution. The object address contains a class identifier and an object identifier and can be used to find the object in the catalog tables. The class identifier is simply the OID of the catalog table where the object resides, and the object identifier is the identifier inside that table. If you create a relation, the OID of the pg_class table will be used as class identifier, so in this case we only need to bother about the object identifier, since we know it is a relation. If you create other kinds of objects that are not stored in the pg_class table, you will get a different class identifier. For example, DefineType will return the class identifier for the pg_type catalog table.
Extension Installation Script
You now have a function for creating an empty table, but it remains to incorporate this into the extension. In previous posts, not much thought was given to how to organize the data, functions, and other objects related to the extension, but now it is quite clear that the best approach is to put all objects in a separate schema (also called namespace internally in the PostgreSQL code). This will allow the extension to create new tables without risking conflicting with existing application data and this is also well-supported by PostgreSQL. Using the CREATE EXTENSION … WITH SCHEMA you can ensure that all object of the extension are created in a separate schema. For example, to create the extension and ensure that all objects are created in the influx schema:
CREATE SCHEMA influx;
CREATE EXTENSION influx WITH SCHEMA influx;If you noticed the definition of the default creation function in Code Block 1 above, the namespace for the new table was taken from the namespace of the function, so this will create all new metrics tables in the same schema as the function. To make this work correctly, we have to modify the installation script to install the table-creating function in the schema used when creating the extension, so we extend the installation script with a new _create function calling the newly created default_create function and place the function in the extension schema.
CREATE FUNCTION _create("metric" name, "tags" name[], "fields" name[])
RETURNS regclass
AS '$libdir/influx.so', 'default_create'
LANGUAGE C;When you have a relocatable extension (relocate = true in the control file), the installation script will be executed in such a manner that any objects created will be put into the schema used for the installation, so there is no need to provide a schema for the objects that are being created. In contrast with previous functions, we here give the name of the function to link to, which is the newly created default_create.
Calling the Table Creation Function
All that remains is now to call the function when an expected table is not found. To deal with this, you need to modify the MetricInsert function to create the table if the table is not found.
void MetricInsert(Metric *metric, Oid nspid) {
Relation rel;
Oid relid;
Datum *values;
bool *nulls;
Oid *argtypes;
AttInMetadata *attinmeta;
int err, i, natts;
relid = get_relname_relid(metric->name, nspid);
if (!OidIsValid(relid))
relid = MetricCreate(metric, nspid);
if (!OidIsValid(relid))
return;
.
.
.
}In this code, you can see that the MetricCreate function is called with the metric and is expected to created the table and return the OID. There is the option of returning InvalidOid in the event that the function do not want to (or cannot) create the necessary table. This allow users to configure the system to not automatically create tables at all, but will result in the metric being thrown away. The MetricCreate function in turn is a little more complicated.
Oid MetricCreate(Metric *metric, Oid nspid) {
Name metric_name;
Oid createoid, result;
ArrayType *tags_array, *fields_array;
Oid args[] = {NAMEOID, NAMEARRAYOID, NAMEARRAYOID};
char *namespace = get_namespace_name(nspid);
List *create_func = list_make2(makeString(namespace), makeString("_create"));
createoid =
LookupFuncName(create_func, sizeof(args) / sizeof(*args), args, true);
if (!OidIsValid(createoid))
return InvalidOid;
if (get_func_rettype(createoid) != REGCLASSOID)
return InvalidOid;
metric_name = palloc(NAMEDATALEN);
namestrcpy(metric_name, metric->name);
tags_array = MakeArrayFromCStringList(metric->tags);
fields_array = MakeArrayFromCStringList(metric->fields);
PG_TRY();
{
result = DatumGetObjectId(OidFunctionCall3(
createoid, NameGetDatum(metric_name), PointerGetDatum(tags_array),
PointerGetDatum(fields_array)));
}
PG_CATCH();
{
result = InvalidOid;
}
PG_END_TRY();
return result;
}The first part of the function locates the _create function in the correct namespace and makes sure that one exists with the correct parameter and return types. Since PostgreSQL uses overloading, the function lookup function LookupFuncName takes an array of parameter types together with a namespace-qualified function name. In this case, we’re looking for a function with the signature _create(Name, Name[], Name[]). One possible improvement here is that the user could have a _create function with the wrong parameter types (an easy mistake to make), and we could reasonably warn the user about this, but it is easy to start to flood the log with warning messages, and we would need to add some logic to deal with this, so we skip this for now. For the same reason we ignore it when the function has the wrong return type. As a result, a _create function with the wrong parameter types or return types will be treated as if the function does not exist.
The second part of the function sets up the values for calling the create function. The first parameter is a name, so we construct a name and copy over the metric name to the allocated memory. The two remaining parameters are arrays of names, so we use the MakeArrayFromCStringList, which is listed below, to build those arrays.
The third, and final, part of the function calls the table creation function. When calling a function, PostgreSQL does a lot of setup to be able to handle, among other things, NULL values, so you need to use one of the functions dedicated to this for calling a PostgreSQL function. In this case, we use OidFunctionCall3, which is the version that accepts an OID of a function and takes three parameters. There are similar functions for different number of arguments, so you also have OidFunctionCall0, … OidFunctionCall9 that takes a different number of parameters, but otherwise behaves the same. We wrap the call into a PG_TRY() … PG_CATCH() to be able to catch any errors generated by the function. This allow the function to generate an error if there is problem with the input and ignore the row.
Just for completeness: here is the function to make an array from a list. It uses the build-in function construct_array to build an array from an array of Datum, so it is necessary to create an array of Datum containing the names.
static ArrayType *MakeArrayFromCStringList(List *elems) {
ListCell *cell;
Datum *datum = palloc(sizeof(Datum) * list_length(elems));
foreach (cell, elems) {
const char *elem = (const char *)lfirst(cell);
Name name = palloc(NAMEDATALEN);
namestrcpy(name, elem);
datum[foreach_current_index(cell)] = NameGetDatum(name);
}
return construct_array(datum, list_length(elems), NAMEOID, NAMEDATALEN, false,
TYPALIGN_CHAR);
}
Comments