
In the post on prepared statement the statements were prepared each time a row is received, which seems like a waste of CPU. After all, the tables do not change, so it should be perfectly OK to just prepare the statement once, save it away in prepared form, and then reuse it for each row (at least until the table definition changes). Fortunately, PostgreSQL has support for this, and in this post you will see how to implement a cache to save prepared statements and re-use them. Since tables occasionally do change, it is also necessary to invalidate the prepared statement if the table actually change definition, so this post will also cover how to implement a cache invalidation handler to invalidate the prepared statements whenever the table definition changes.
Implementing a cache for storing prepared statements will cover three steps:
- Creating a cache for the prepared statements that will store one prepared statement for each relation.
- Using the cache to either retrieve a prepared statement for a relation or prepare a new statement and store in the cache.
- Add logic to invalidate the cache when the relation changes definition.
Creating a Cache for Prepared Statements
The first step is to implement the prepared statements cache that have one prepared statement for each relation. Since the metrics are stored in the relation with the same name as the measurement in the line, there will be a single prepared statement for each relation. This means that you can use the relation OID as the key and store an entry with a OID and a prepared statement pointer. This requires a simple mapping from keys to entries and fortunately PostgreSQL has a dynamic hash table implementation that can be used for this purpose. It works by keeping a set of fixed-size hash entries in a table, which is initialized using the hash_create function and then modify or search the hash table using hash_search (sic).
To create a hash table, the first thing that is needed is an structure that will hold the information for each entry.
typedef struct PreparedInsertData {
Oid relid;
SPIPlanPtr pplan;
} PreparedInsertData;
typedef PreparedInsertData *PreparedInsert;The hash table entry is just a normal C struct, so nothing in particular that needs to be done there, but it is important that the key is always first in the structure since the hash table implementation relies on this. It is easiest to let the first field of the structure be the key and the rest of the structure contain the data that you want to store. In this case the key will be the relation OID, but if you need a more complex key it is usually easiest to define a special structure for holding the entire key. The rest of the fields in the structure contain the data to store, which in this case is a pointer to the prepared plan.
Creating the hash table is straightforward using the hash_create function. The function takes a hash control structure, HASHCTL, containing the information necessary for configuring the hash table. The hash control structure is highly configurable and contains a lot of different fields. To decide which fields to use, hash_create accepts a list of flags that activate usage of different fields of the structure. Most of the values can be zero-initialized, but two of the entries are important to set correctly: keysize and entrysize.
static HTAB *InsertCache = NULL;
void InitInsertCache(void) {
HASHCTL hash_ctl;
memset(&hash_ctl, 0, sizeof(hash_ctl));
hash_ctl.keysize = sizeof(Oid);
hash_ctl.entrysize = sizeof(PreparedInsertData);
InsertCache =
hash_create("Prepared Inserts", 128, &hash_ctl,
HASH_ELEM | HASH_BLOBS);
}As the names suggests, the field keysize define the size of the key and entrysize defines the size of the entry in the hash table. Note that the entry size is the size of the entire structure, including the key, so the entry size has to be larger than (or equal to) the key size.
The flag HASH_ELEM is necessary to store the key size and the entry size in the hash table. If it is not passed—which is slightly odd, but allowed—the key size and entry size is set to some quite useless default values (the size of a pointer and twice the size of a pointer, respectively). The flag HASH_BLOBS means that the key comparison will be done with memcmp(3), otherwise, key comparison will be done using strcmp(3). In this case, a simple integer is used (the OID) so comparison should be done in binary.
In addition to the hash control structure and the flags, it is also necessary to pass the initial size of the hash table and a few flags when creating the hash table. The initial size should be close to the expected size, but the hash table implementation will increase the size if necessary. PostgreSQL picks 128 as initial size in most cases, so the same is done here.
The hash table implementation is quite powerful and here only the most basic usage is demonstrated, which is sufficient to implement a cache for prepared statements. The other fields of the hash control structure are available for more advanced usage, but requires other flags to be passed in. If you want to learn more about the implementation and understand what options are available, have a look at src/backend/utils/hash/dynahash.c in the source code.
The next step is to add support for finding existing entries, or add a new one if necessary. The hash table implementation handles both addition, searching, and removal of entries using a single function: hash_search.
void *hash_search(HTAB *hashp, const void *keyPtr, HASHACTION action, bool *foundPtr);The function accepts a pointer to the key to look for and an action. It will always return a pointer to the entry, if it exist, but can add or remove a hash entry for that key (or do nothing with it) depending on the value of the action parameter. It also accept a pointer to a variable that will indicate if an entry was found or not. In Table 1 you can see the possible values for the action and what they will do.
HASH_FIND | Look up entry by key in the table and return a pointer to it, if it exists. Return NULL if it doesn’t exist. |
HASH_ENTER | Look up entry by key in the table and return a pointer to it. Create a new entry if one does not exist. |
HASH_REMOVE | Look up entry by key in the table and delete it. Return a pointer to the entry, if it exists. |
Using hash_search it is possible to implement the function to either find an entry or create a hash entry using HASH_ENTER.
static HTAB *InsertCache = NULL;
.
.
.
bool FindOrAllocEntry(Relation rel, PreparedInsert *precord) {
const Oid relid = RelationGetRelid(rel);
bool found;
if (!InsertCache)
InitInsertCache();
*precord = hash_search(InsertCache, &relid, HASH_ENTER, &found);
return found;
}The function FindOrAllocEntry will return a pointer to the existing entry if it exists, or create a new hash entry and return a pointer to it if one does not exist. The code initializes the variable InsertCache if it is not initialized, and tries to find the record using the provided relation OID. If one is not found, an entry is added and a pointer to it returned. To use this function, you have to check if a new entry was returned or not and use this to decide if you should prepare the statement or not, which is the topic of the next section.
Preparing the Statement for the Cache
With a cache implementation you can now start to populate it with prepared statements and ensure that they are only prepared when they are not present in the cache. To simplify the code, just create a dedicated function PrepareRecord for preparing the statement using the code from the previous post.
void PrepareRecord(Relation rel, Oid *argtypes, PreparedInsert record) {
TupleDesc tupdesc = RelationGetDescr(rel);
StringInfoData stmt;
SPIPlanPtr plan;
const Oid relid = RelationGetRelid(rel);
int i;
initStringInfo(&stmt);
appendStringInfo(
&stmt, "INSERT INTO %s.%s VALUES (",
quote_identifier(SPI_getnspname(rel)),
quote_identifier(SPI_getrelname(rel)));
for (i = 0; i < tupdesc->natts; ++i)
appendStringInfo(&stmt, "$%d%s", i + 1,
(i < tupdesc->natts - 1 ? ", " : ""));
appendStringInfoString(&stmt, ")");
plan = SPI_prepare(stmt.data, tupdesc->natts, argtypes);
SPI_keepplan(plan);
record->relid = relid;
record->pplan = plan;
}Most of the code is just picked from the previous post, especially the way on how to build the insert statement from the tuple descriptor. There is, however, one culprit in that when a statement is prepared, the memory is allocated in the SPI procedure context, which has lifetime that is pretty short: it will be deleted when SPI_finish is called, which is typically when the procedure has finished executing. This is not particularly suitable for a cached prepared statement since it should be possible to reuse it at a later time. Instead, the function SPI_keepplan will move the memory for the prepared statement to be a child of the CacheMemoryContext, which is much more long-lived (typically, the same as the top memory context, which exists for the lifetime of the process.)
The memory is actually allocated in a dedicated memory context that is a child of the SPI procedure memory context, so the SPI_keepplan function will re-parent the memory context for the prepared statement. By creating a dedicated memory context for the prepared statement, the re-parenting operation is very cheap and just requires changing a pointer.
To check if it is necessary to prepare the statement, you can check if a new entry was created by checking the return value of FindOrAllocEntry and only prepare the statement using PrepareRecord if it is actually necessary.
PreparedInsert record;
.
.
.
if (!FindOrAllocEntry(rel, &record))
PrepareRecord(rel, argtypes, record);Invalidating cache entries
Since the prepared statements are created based on the table definition, they do not need to be changed unless the table definition actually changes. This means that it will not be necessary to prepare the statement for each received row, but it is necessary to invalidate the prepared record when the table definition changes. To handle this, PostgreSQL has a concept called invalidation handlers which are called whenever a cache might have to be updated. There are two types of invalidation handlers: relation invalidation handlers and system cache invalidation handler. The system cache invalidation handlers allow an invalidation function to be called when a specific system cache is invalidated and will not be covered here, but the relation invalidation handlers are called whenever a relation is invalidated and is perfect for this case.
The relation invalidation handler is called with two parameters: a datum and a relation OID. The datum can be passed when registering the invalidation handler and can be used to, for example, tell what cache to invalidate. The second parameter is the relation that is invalidated.
void InsertCacheInvalCallback(Datum arg, Oid relid) {
if (InsertCache) {
bool found;
PreparedInsert record =
hash_search(InsertCache, &relid, HASH_REMOVE, &found);
if (found)
SPI_freeplan(record->pplan);
}
}The invalidation handler for the prepared inserts cache uses the hash_search function to remove the record for the relation from the InsertCache and then free the plan using SPI_freeplan. In other cases it is not necessary to explicitly free the memory for allocated objects since they are allocated in memory contexts that will be reset at appropriate times, but in this case the memory context is a child of the CacheMemoryContext, which is long-lived and hence it is necessary to free it explicitly or have a memory leak.
The invalidation handler can now be registered with the CacheRegisterRelcacheCallback when the worker is started. Here 0 is passed as datum value and since it is not used in the invalidation handler, anything could be passed. This means that arg will be zero in the invalidation handler above. Note that the cache is per-process and not shared between several processes. It is possible to create a shared cache, but that would require shared latches to protect it which affect performance even if the cache is mostly read-only. Since table changes are rare, it is cheaper to just prepare the statements for each process and avoid the extra latches.
void WorkerMain(Datum arg) {
.
.
.
pgstat_report_activity(STATE_RUNNING, "initializing worker");
CacheRegisterRelcacheCallback(InsertCacheInvalCallback, 0);
.
.
.
}That’s it! You now have a InfluxDB line protocol reader that you can use. A very basic one, but it works.
What about performance?
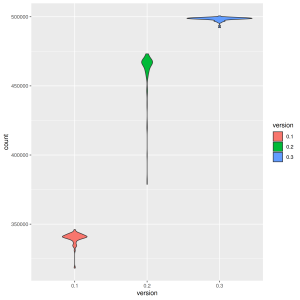
The obvious question to ask is how performance was affected with these changes. Using influx-faker again you can see in Figure 1 that it performs about 40% better than the first implementation. It is also more stable since there is just a cache lookup to be done for each row compared to parsing and preparing a statement for each row.
Now, remember that the influx faker sends rows as fast as it can and it will be very hard to read all rows that are sent to it. This is a great improvement, but in the next few post you will see a few ways that this can be improved even further. I’m not sure if it will be possible to match the speed of the influx-faker, but it’s worth to give it a try.

Comments